
一转眼两个月过去了,真的是过得毫无察觉,这两个月其实被同学拉着一起参加了腾讯广告算法大赛,第一次打比赛,初赛47名,决赛,emmmm,没好好参加,最后都没提交结果,根本来不及跑特征,跑一个模型,基本1天+,最开始的时候根本没机器跑,所以基本就是停滞不前,后面用腾讯云代金券开了96G内存的服务器,可以跑数据,后面又租了一台GPU服务器,内存200G,但是最后只有一周的时间,两天服务器分别跑DNN和LGB,但是跑模型实在太慢,10000迭代的模型太慢。
比赛概括
比赛官网:http://algo.qq.com,腾讯举办的第二届比赛,我是第一次参加大数据类型的比赛。
比赛总共分为3个阶段:
- 初赛:4月18号 12:00 - 5月23号 11:59:59
- A阶段:4月18号 12:00 - 5月19号 11:59:59
- B阶段:5月19号 12:00 - 5月23号 11:59:59
- 复赛:5月24号 12:00 - 6月13号 11:59:59
- A阶段:5月24号 12:00 - 6月9号 11:59:59
- B阶段:6月9号 12:00 - 6月13号 11:59:59
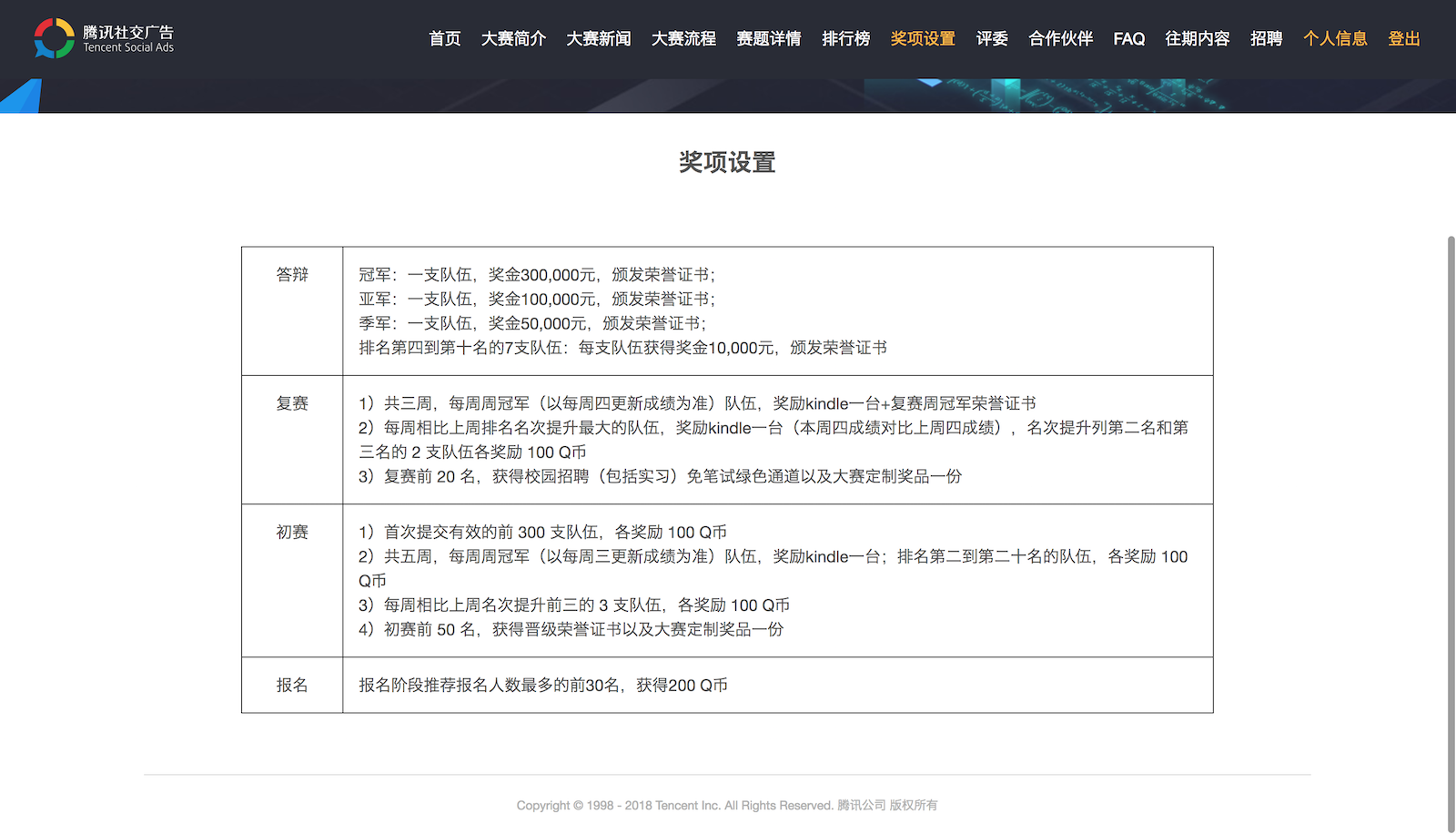
初赛的成绩主要以B阶段提交的最好成绩作为最后成绩,初赛前50有证书+礼品,复赛前20有奖项:
- 第一名:30万+证书
- 第二名:10万+证书
- 第三名:5万+证书
- 第4到第10名:1万+证书
- 第11到20名:校招免笔试绿卡+礼品
不得不说,腾讯还是很大气,在比赛方面,工作人员各方面的工作都做的比较到位,而且人也很好。关于比赛的详细情况,可移步官网
数据介绍
这次比赛实际上是一个CTR(Click through rate),广告点击率问题,即给你用户和广告信息,然后预测用户是否会点击所投放的广告,初赛数据与复赛数据一致,包含四张数据表格:
- train.csv:训练数据表,字段包含:aid,uid,label,aid为具体广告ID,uid为用户具体ID,ID与用户或者广告一一对应,label取值为1或者-1,分别表示相关与不相关,相关意味着用户会点击广告;
- adFeature:广告属性数据表,字段包含:aid,advertiserId,campaignId,createId等(由于字段过多,不进行一一复述,详细请查阅参赛手册,官网信息可能会更新,所以手册已经下载保存在自己的服务器上。
- userFeature:用户属性数据表,字段包括:uid,age,LBS,gender等
- test.csv:测试数据集,字段包括:aid,uid,需要预测给定的aid与uid之间的相关性,给出概率
评估方法采用AUC标准,AUC主要用在分类器评判上,对于正负样本不均匀不敏感
此次比赛,正负样本比率:1:19,数据处理上,主要用的是lightgbm,fm,ffm,deepfmm,没有针对不均匀样本进行特殊处理。
补充:详见知乎
- AUC(Area under curve):ROC曲线下的面积,含义为一个二分类器下任取样本正负样本各一个,分类器将正样本判断为正的概率P1,负样本为P0,P1 > P0的概率几位AUC的值
- ROC(Receiver operating characteristic curve):x轴为假阳率,y轴为真阳率
- 假阳率:混淆矩阵中将负样本预测为正样本的数量除以全部预测为正样本的数量,即: FP/(TP+FP)
- 真阳率:混淆矩阵中将正样本预测为正样本的数量除以全部预测为正样本的数量,即: TP/(TP+FP)
- 召回率:对于样本而言,原来的正样本预测为正样本(TP),正样本预测为负样本(FN),预测为正样本的准确率,TP/(TP+FN)
- 精确率:对于预测结果而言,原来正样本预测为正样本(TP),原来负样本预测为正样本(FP),TP/(TP+FP)
初赛数据,解压后近5G,训练数据集有800w+样本,测试数据集200w+,用户数据集有1100w+条目,广告数据集有179条,数据拼接后大小近8G
复赛数据,解压后近16G,训练数据集有4500w+样本,测试数据集1100w+,数据拼接后大小近20G
参赛经验
第一次参加比赛,所以毫无经验,不过有大佬开源baseline,在此十分感谢bryan大佬的开源,让第一次参加的小白能够快速入门,还有官方群里的那些开源的大佬。
参赛的历程如下:学习baseline —-> 自己写baseline —-> 统计分析做特征(统计特征以及交叉组合统计特征) —-> 学习其他模型 —-> 跑模型并提交成绩
baseline的学习
在你什么都不懂的时候,快速入门其实最好的资料就是有一份完整的代码,能够让你了解到整个流程,包括数据处理,模型选择,参数设计,到最后的模型应用和预测,对着代码,将代码涉及到的所有内容一点点学习,不要求所有的原理全部弄清楚,但是能达到应用和复现的程度。本次比赛的流程图如下:
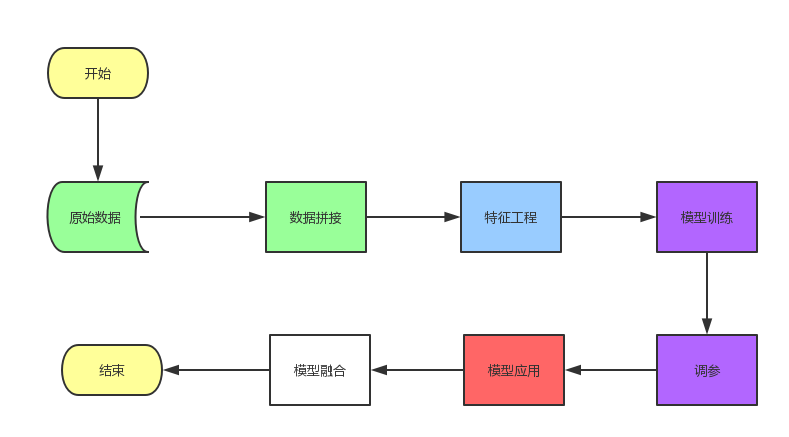
baseline的代码包括除了上图模型融合的流程,其余的都包括了,baseline用的模型就只有一个lightgbm(决策树模型,脑图)
具体知识点
pandas
见pandas入门
jupyter notebook
单元格多个输出(更多技巧)
1
2from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
linux
- 后台运行Python脚本并实施输出
- 使用nohup命令,将输入重定向到nohup.out文件
- 使用文件IO,并实时进行缓冲区清楚,file.flush,这样就能及时地将内容写入到文件里
- CPU内存占用查看工具:htop,安装
sudo apt-get install htop
模型
- 可使用Libsvm格式进行训练,能用极大节约内存(python 接口运行内存需要100G,使用Libsvm格式只需要不到40G就能训练)
lightgbm
- 支持继续训练,特征必须相同,否者无效
python
- 进度条tqdm
- 稀疏矩阵存储npz
- 文件存储hdf,pickle,json.dump,joblib
Github代码
随手一个star,比心!👉👉👉👉👉👉 传送门👈👈👈👈👈👈
目录结构
项目下有四个目录:
- lgb_libsvm
- ffm代码
- deep_ffm代码
- 开源baseline
lgb_libsvm
lgb_libsvm下的代码是使用libsvm格式进行lgb训练和预测的代码,这个目录下就是我的写的代码了,ffm和deepffm的则是辉哥整理和编写的代码
- degub文件夹:测试csv转化成libsvm的例子的文件夹
- demo文件夹:小样本demo文件夹
- twofile:将两个csv文件拼接然后转化为libsvm文件
- feature_engineering:基于libsvm格式,lgb去选特征,验证特征工程是否有效
- offline_datasets:线下测试的数据文件夹(train_test_split为编译过的可执行性文件,chmod +x ,然后./train_test_split就能看到用法,实验室的大佬用C++写的,速度特别快)
- iioiio:实验室大佬c++写的数据集验证集划分
- lgb_config:lgb训练参数文件
- Ljh:辉哥整理的特征工程代码
- shell_command:训练流程自动化shell脚本(最后来不及,没用到,也没写完)
- submission:提交结果文件夹
开源baseline
bryan大佬的开源,帮助了很多跟我一样的小白,在此表示感谢,把baseline吃透,包括one-hot和CountVector,然后对着sklearn的源码和例子看一下,就能了解到特征的基本处理流程,baseline的主要知识点如下:
- 数据读取、拼接和转化:原来的4张表拼接成一张表,这里csv转化为pandas的DataFrame,然后使用df(dataframe)进行操作,pandas入门,文件读取和字符串操作(userdata的转化)
- one-hot:处理离散型数据,且相互之间独立没有联系,由于机器学习中需要用计算机能够表达的形式来表示数据,所以one-hot就是一种处理形式,简单介绍(后面再单独写一篇博文介绍下,因为之前看的别人写的都不够全面,包括one-hot的特点,使用意义)
- CountVector:也是处理离散型数据,跟BOW(Bog of words)一样
- Lightgbm python接口使用和参数设置
- 参数调整
- Lightgbm模型学习(决策树模型、xgboost等)
FFM代码
fm和ffm:ffm(filed Factorization Machines)是在fm的基础上改进的,学习资料美团的技术博客、fm(1、2)和ffm(1、2)的论文

